41 keras reuters dataset labels
Visual analytics tool for the interpretation of hidden ... - Springer Projection for the Reuters dataset. The data points of the sequences are colored according to their actual class instead of the classification result. In addition, points that belong to correctly classified sequences are more transparent. This visualization helps identify areas where hidden states generate possibly incorrect model outputs. Multitask Learning - Manning First, let us discuss how to load the sentiment data into our model. The overall schema is the following. Figure 1. Sentiment data processing schema. The following procedure converts our data into feature vectors, labeled with integer-valued class labels. Listing 1: Load sentiment data.
RNN (Recurrent Neural Network) Tutorial: TensorFlow Example The data preparation for Keras RNN and time series can be a little bit tricky. First of all, the objective is to predict the next value of the series, meaning, you will use the past information to estimate the value at t + 1. The label is equal to the input sequence and shifted one period ahead.

Keras reuters dataset labels
tfds.as_dataframe | TensorFlow Datasets ds. tf.data.Dataset. The tf.data.Dataset object to convert to panda dataframe. Examples should not be batched. The full dataset will be loaded. ds_info. Dataset info object. If given, helps improving the formatting. Available either through tfds.load ('mnist', with_info=True) or tfds.builder ('mnist').info. › python › examplePython Examples of keras.datasets.reuters.load_data def load_retures_keras(): from keras.preprocessing.text import Tokenizer from keras.datasets import reuters max_words = 1000 print('Loading data...') (x, y), (_, _) = reuters.load_data(num_words=max_words, test_split=0.) print(len(x), 'train sequences') num_classes = np.max(y) + 1 print(num_classes, 'classes') print('Vectorizing sequence data...') tokenizer = Tokenizer(num_words=max_words) x = tokenizer.sequences_to_matrix(x, mode='binary') print('x_train shape:', x.shape) return x.astype ... nlp - How to get fine-grained sentiment score from text data under ... $\begingroup$ @Ashwiniku918 Thank you for your reply. I want to use Reuters news dataset and get the sentiment score of the news every day but its sentiment is unlabelled. I now plan to train a sentiment classification model on a large text dataset labelled with sentiment first, and then fine-tune it on a small news dataset (from kaggle), and finally use the model on Reuters news dataset ...
Keras reuters dataset labels. Classifying Movie Reviews: Keras - Junhyung Park In this post, I went over a well-known, basic example of a binary sentiment analysis of movie reviews using neural networks. In the next post, I will continue to go down the rabbit hole in the world of neural networks, working on the Reuters and the Boston housing price datasets. Thanks for reading. Tags: Keras, Tensorflow. Categories: study read images from folder python tensorflow Example 18. PREDICT.PY. MNIST, CIFAR10, CIFAR100, IMDB, Fashion MNIST, Reuters newswire, and Boston housing price datasets are available within Keras. You will read the images using OpenCV, one-hot the class labels, visualize the images with labels, normalize the images, and finally split the dataset into train and test set. keras.io › api › datasetsReuters newswire classification dataset - Keras This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic Reuters-21578 dataset, but the preprocessing code is no longer packaged with Keras. See this github discussion for more info. Each newswire is encoded as a list of word indexes (integers). › keras-datasetsKeras Datasets | What is keras datasets? - EDUCBA # Reuters classification dataset for newswire. Reuters classification dataset for newswire is somewhat like IMDB sentiment dataset irrespective of the fact Reuters dataset interacts with the newswire. It can consider dataset up to 11,228 newswires from Reuters with labels up to 46 topics. It also works in parsing and processing format.
Handwriting recognition - Keras In this section, we will implement it and use it as a callback to monitor our model. We first segregate the validation images and their labels for convenience. validation_images = [] validation_labels = [] for batch in validation_ds: validation_images.append(batch["image"]) validation_labels.append(batch["label"]) Now, we create a callback to ... dataset_cifar100: CIFAR100 small image classification in keras: R ... Description Dataset of 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images. Usage 1 dataset_cifar100 (label_mode = c ("fine", "coarse")) Arguments label_mode one of "fine", "coarse". Value Lists of training and test data: train$x, train$y, test$x, test$y . stackoverflow.com › questions › 45138290How to show topics of reuters dataset in Keras? - Stack Overflow Jul 17, 2017 · 1 Answer. Associated mapping of topic labels as per original Reuters Dataset with the topic indexes in Keras version is: ['cocoa','grain','veg-oil','earn','acq','wheat','copper','housing','money-supply', 'coffee','sugar','trade','reserves','ship','cotton','carcass','crude','nat-gas', 'cpi','money-fx','interest','gnp','meal-feed','alum','oilseed','gold','tin', 'strategic-metal','livestock','retail','ipi','iron-steel','rubber','heat','jobs', ... Multi-Label Text Classification Using Keras - Medium The dataset consists of a text blob of 300k+ Wikipedia articles along with taxonomic hierarchical classes as labels. There are 298 unique labels across the dataset.
Deep Learning Part 4 - Classification and Regression | Articles Loading the Reuters dataset from tensorflow.keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( path='reuters.npz', num_words=10000, skip_top=0, maxlen=None, test_split=0.2, seed=113, start_char=1, oov_char=2, index_from=0) Part A: A Practical Introduction to Text Classification - Medium Text classification is a machine learning technique that assigns a set of predefined categories ( labels/classes/topics) to open-ended text. The categories depend on the selected dataset and can... Can I extract labels of an image dataset from image names using Keras ... Keras usually wont load all data once to save memory, it can't have naming disintegration.. as files are unsorted you can try using below snippet with shutil and os to segregate the files accordingly and load folder based data generators to feed data to model. import os from shutil import move folder = 'data folder path' for clas in os.listdir(folder): for file in os.listdir(os.path.join ... Using regression to predict house prices using Tensorflow and Keras In this example we will use the Boston housing price dataset to predict house prices based on several features such as crime rate, local tax property rate and so on. The biggest difference to the previous examples here is that we do not predict fixed classes. This time we predict a continous value. Prequesites This is the third part of my Tensorflow and Keras Sample series. To better ...
Brad Dickinson | Creating and deploying a model with Azure Machine Learning Service
NLP: Text Classification using Keras - linkedin.com We have to import these datasets from Keras. After importing, its feature dataset and label dataset are individually stored in two tuples. Each tuple contains both training and testing portions....

Training with Image Data Augmentation in Keras
The Whale Optimization Algorithm Approach for Deep Neural Networks Data sets and labels were taken from the UCI machine learning repository. They included Fashion-MNIST images classification as well as Reuters text data classification. Fashion-MNIST is a replacement of a popular benchmark MNIST dataset. We decided to use Fashion-MNIST because, as its authors suggest, the original MNIST is too simple for modern ...
Rhyme - Project: Multilayer Perceptron Models with Keras
Similarity-based second chance autoencoders for textual data In this section, we analyze the performance of SCAT and SSCAT compared to the models mentioned above on two tasks: multi-class classification using the dataset of 20 Newsgroups and multi-label classification using the Wiki10+ and Reuters datasets. The results of both tasks are reported in Table 4. We also compare and report the topic coherence ...

Deep Learning Approach to Binary Classification of Molecules using the MNIST dataset, classification of reviews of movies, with the IMDB database, A Reuters dataset with 46 categorical outputs, and also the Boston housing dataset among others. The motivation

Chapter 3 news classification: multi classification problems from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data (num_words = 10000) # Test whether the load is successful print (len (train_data)) print (len (test_data)) # print (train_data [10]) 3-13 decoding index into news text

Classifying Reuters Newswire Topics with Recurrent Neural Network | by Phuong Truong | Medium
image_dataset_from_directory : Create a dataset from a directory Then calling image_dataset_from_directory (main_directory, labels='inferred') will return a tf.data.Dataset that yields batches of images from the subdirectories class_a and class_b, together with labels 0 and 1 (0 corresponding to class_a and 1 corresponding to class_b). Supported image formats: jpeg, png, bmp, gif.
cannot import name 'detect_lp' · Issue #14208 · keras-team/keras · GitHub
Using tf.keras.utils.image_dataset_from_directory with label list ... image_dataset_from_directory() takes directories in current path as input labels and then open those files and take the images inside it as data. In your case, it is reading the images/data as classes and trying to open them which is not possible and hence the errors.
31 Keras Multi Label Classification - Labels For You
keras.io › api › datasetsDatasets - Keras The tf.keras.datasets module provide a few toy datasets (already-vectorized, in Numpy format) that can be used for debugging a model or creating simple code examples. If you are looking for larger & more useful ready-to-use datasets, take a look at TensorFlow Datasets.

Image Classification using CNNs in Keras | Learn OpenCV
deeplearningwithpython - Flip eBook Pages 101-150 | AnyFlip from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=10000) As with the IMDB dataset, the argument num_words=10000 restricts the data to the 10,000 most frequently occurring words found in the data. You have 8,982 training examples and 2,246 test examples: >>> len(train_data) 8982

Rhyme - Project: Multilayer Perceptron Models with Keras
Using tf.keras.utils.image_dataset_from_directory with label list from the document image_dataset_from_directory it specifically required a label as inferred and none when used but the directory structures are specific to the label name. I am using the cats and dogs image to categorize where cats are labeled '0' and dog is the next label.
keras image data generator tutorial | keras imagedatagenerator example
NLP: Text Classification using Keras We have to import these datasets from Keras. After importing, its feature dataset and label dataset are individually stored in two tuples. Each tuple contains both training and testing portions....

Data Augmentation tasks using Keras for image data | by Ayman Shams | Medium
github.com › blob › masterkeras/reuters.py at master · keras-team/keras · GitHub This is a dataset of 11,228 newswires from Reuters, labeled over 46 topics. This was originally generated by parsing and preprocessing the classic: Reuters-21578 dataset, but the preprocessing code is no longer packaged: with Keras. See this [github discussion]( ) for more info.

How To Load Imdb Data Set In Tensorflow? - Surfactants Find available datasets. Click on the dataset you want to load. tfds.load. tfds.builder. Data structures should iterate over dataset sets. As a dict. Using datasets to benchmark your process. Developing a pipeline of every aspect of data. Visualization. tfds.as_dataframe. Metadata (labels, image shapes, etc.) of the dataset can be accessed.
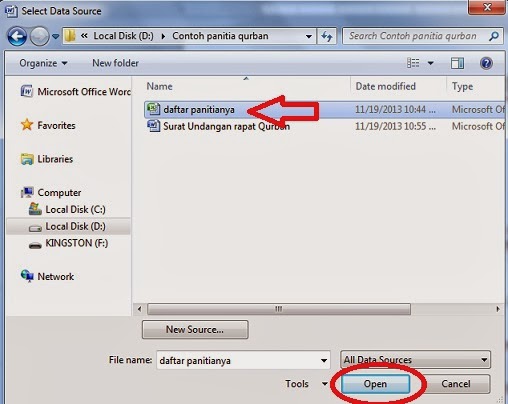
Cara Membuat Mail Merge di Word 2007 - 2010 ~ GORESAN TINTA EMAS
Detecting Fake News With Deep Learning - Medium Now let's give the data labels and combine them into one dataset for training, then train/test split them. # Give labels to data before combining fake ['fake'] = 1 real ['fake'] = 0 combined = pd.concat ( [fake, real]) ## train/test split the text data and labels features = combined ['text']

github.com › keras-team › kerasWhere can I find topics of reuters dataset #12072 - GitHub Jan 18, 2019 · In Reuters dataset, there are 11228 instances while in the dataset's webpage there are 21578. Even in the reference paper there are more than 11228 examples after pruning. Unfortunately, there is no information about the Reuters dataset in Keras documentation. Is it possible to clarify how this dataset gathered and what the topics labels are?
ImageDataGenerator.flow_from_dataframe keeps loading when directory has subdirectories · Issue ...
Multiclass classification with Tensorflow and Keras functional API First of all we have to load the training data. Which we can do like this: from tensorflow.keras.datasets import reuters The dataset consists of 11.228 newswires in 46 categories - labels. Like in the last example we will anly load the 10.000 most used word since words that are used not very often aren't helpful for catigorization.

Sample Gallery — zetane documentation
Create and explore datasets with labels - Azure Machine Learning ... Export data labels. When you complete a data labeling project, you can export the label data from a labeling project. Doing so, allows you to capture both the reference to the data and its labels, and export them in COCO format or as an Azure Machine Learning dataset. Use the Export button on the Project details page of your labeling project. COCO
Post a Comment for "41 keras reuters dataset labels"